WordStat
“For those who have ever needed to find themes or relationships in verbatim responses, focus group transcripts, or other text sources, WordStat is very attractive indeed.” Marketing Research Magazine, Spring 2006
WordStat ist ein Textanalysemodul, das speziell für die Antworten auf offene Fragen, Interviews, Zeitungsartikel, öffentliche Reden, elektronische Kommunikation usw. entwickelt wurde. Das Programm kann sowohl für die automatische Kategorisierung von Texten mittels eines Kategoriensystems (Diktionär) als auch für manuelle Codierung genutzt werden. In der neuesten Version 7.1 wird die Verarbeitung von Geodaten unterstützt.
Mit WordStat können bereits existierende Kategoriensysteme auf neue Textkorpora angewendet oder neue entwickelt und validiert werden. Mittels der manuellen Codierung kann WordStat für eine systematische Anwendung von Codierungsregeln und Entdeckung von Unterschieden im Wortgebrauch zwischen Gruppen von Individuen, Revision bereits existierender Codierungen mittels KWIC (Keyword-In-Context) und für die Berechnung von Intercoderreliabilitäskoeffizienten eingesetzt werden.
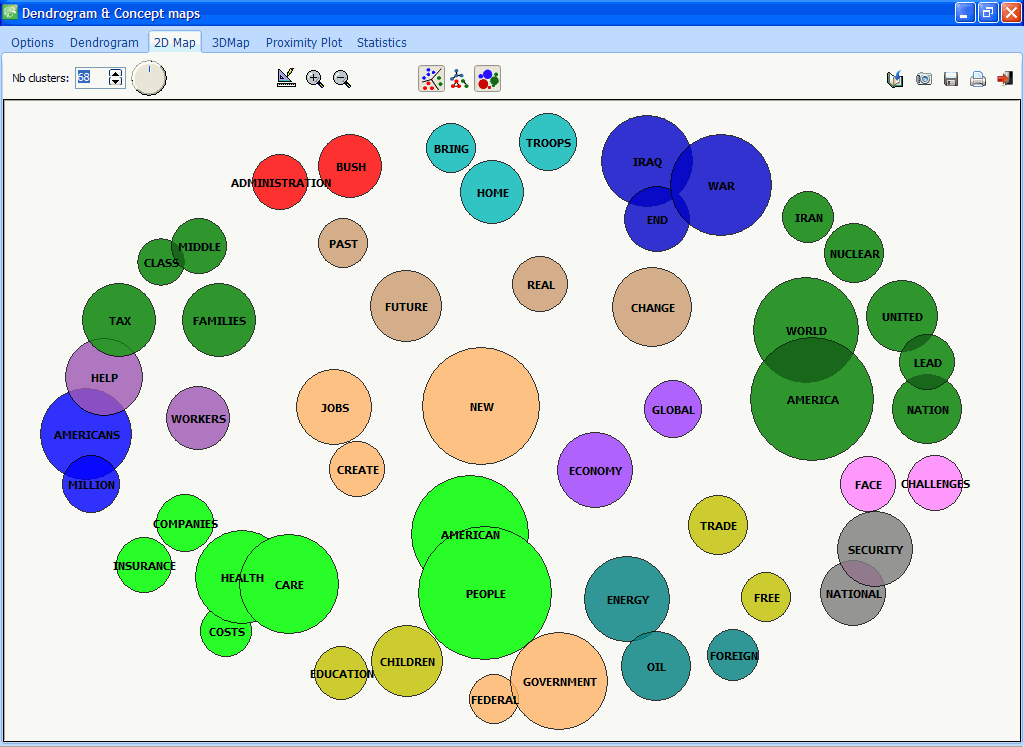
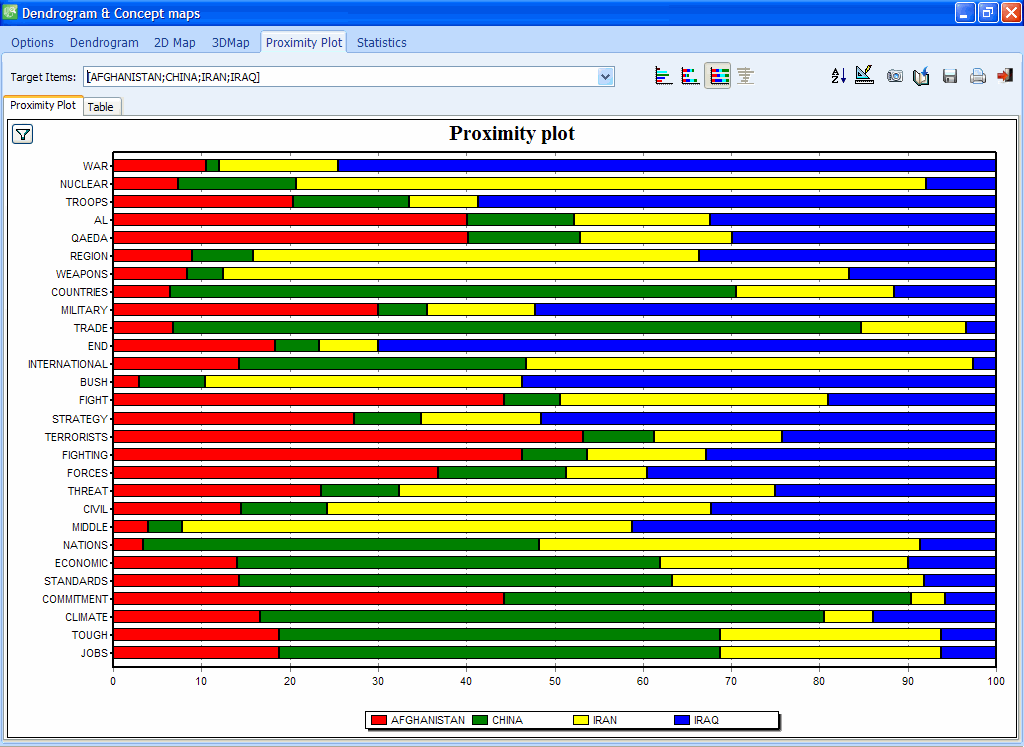
WordStat enthält zahlreiche exploratorische datenanalystische- und graphische Tools, mit denen man die Beziehung zwischen Inhalten von Dokumenten und Informationen, die in kategoriellen oder numerischen Variablen wie Geschlecht oder Alter, Jahr der Publikation etc. vorliegen, untersuchen kann. Beziehungen zwischen Wörtern oder Kategorien und auch die Ähnlichkeit von Dokumenten kann durch hierarchische Clusteranalysen oder multidimensionale Skalierung entdeckt werden. Korrespondenzanalyse und Heatmap-Plots dienen zur Untersuchung von Beziehungen zwischen Schlüsselwörtern und verschiedenen Gruppen von Individuen.
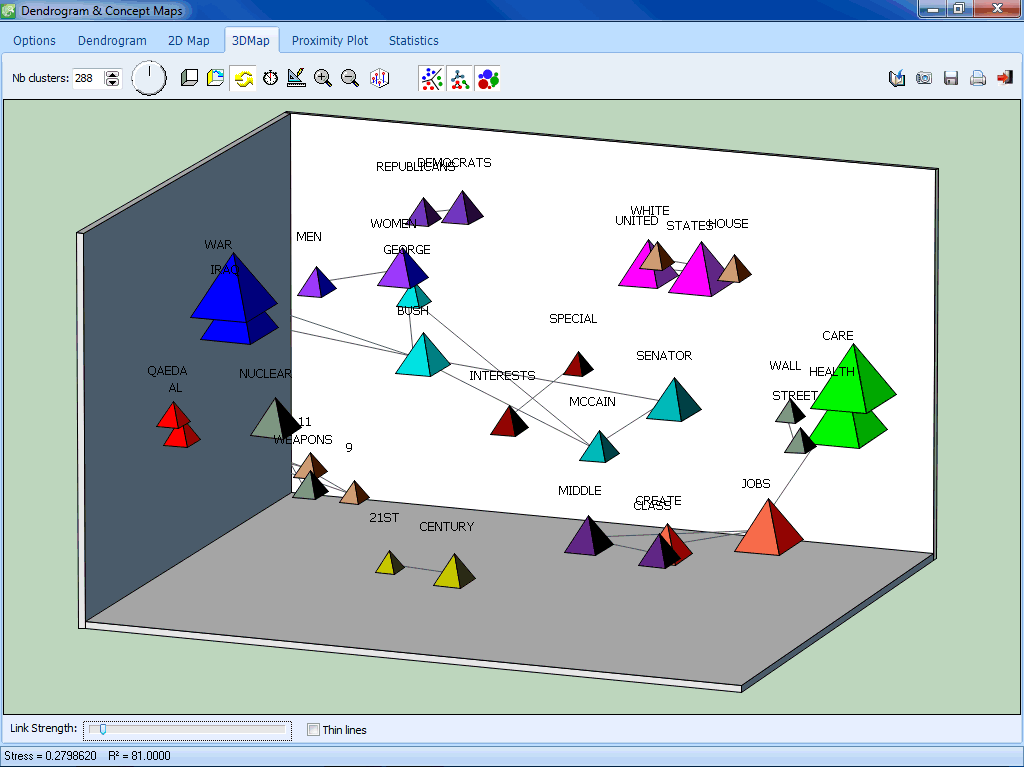
Hauptmerkmale
- Integration von Textmining- und Visualisierungswerkzeugen (Clusteranalyse, multidimensionale Skalierung, Korrespondenzanalyse, Heatmaps)
- Hierarchische Kategoriensystem oder Taxonomien, die Wörter, Phrase und Ähnlichkeitsregeln erlauben.
- Vokabular und Phrasensucher für die Extraktion von Fachausdrücken und wiederkehrenden Ideen und Themen.
- Keyword-in-context und Werkzeuge zur einfachen Identifikation von relevanten Textsegmenten.
- Algorithmen des maschinellen Lernens für die automatische Klassifikation von Dokumenten (Naive Bayes und K-Nearest Neighbors) mit automatischer Auswahl und Validierungswerkzeugen.
- Import von Dokumenten und Export von Daten, Tabellen und Grafiken in den gängigen Standard- formaten.
Neu in Version 7.0
1. Topic extraction tool
WordStat extrahiert aus den Texten die wichtigen Begriffe.
2. Rechtschreibfehler
eine neue intelligente Behandlung von Rechtschreibfehlern wurde eingebaut.
3. Wortstammreduktion
gibt es jetzt für 18 Sprachen languages: englisch, französisch, spanisch, baskisch, katalanisch, tschechisch, italienisch, deutsch, dänisch, holländisch, finnisch, ungarisch, norwegisch, portugiesisch, rumänisch, schwedisch und russisch.
Wichtig: WordStat ist alleine nicht lauffähig. Es ist entweder eine SimStat oder eine QDA-Miner Lizenz erforderlich. Wir bieten entsprechende Kombinationen Bundles mit Rabatt an.